
최근 방송미디어 아카이브를 구축하여 학술연구·교육·창작 등에 공적으로 활용하는 사례가 많다. 특히 인공지능(AI) 기술을 활용하여 축적된 영상 콘텐츠의 정보를 수집하고 좀 더 정확히 분석하는 과정에서 미디어 제작뿐만 아니라 다양한 분야의 학술 연구와 접목하는 사례가 늘어나고 있다. 이 글에서는 국내에는 아직 부재한 방송미디어 아카이브 기관의 활동을 중심으로 살펴보고자 한다. 최근 발표된 국제 공공영상아카이브의 인공지능 프로젝트 가운데 프랑스 국립방송아카이브 이나(INA)와 벨기에 플랑드르 공공영상아카이브 미무(Meemoo) 두 사례를 중심으로 살펴보았다. 공공 차원에서 운영되는 아카이브 기관이 각국 공영방송사 등 방송·미디어사와 함께 인공지능(AI) 학습데이터 수집·분석·활용 과정을 살펴보고 국내에서 참고할 점이 무엇인지 살펴보았다.
1. 들어가며
최근 방송미디어 아카이브를 구축하여 학술연구·교육·창작 등에 공적으로 활용하는 사례가 많다. 특히 인공지능(AI) 기술을 활용하여 축적된 영상 콘텐츠의 정보를 수집하고 좀 더 정확히 분석하여 미디어 제작뿐만 아니라 다양한 학술 연구 분야와 접목하는 사례가 늘어나고 있다. 이 글에서는 국내에는 아직 부재한 방송미디어 아카이브 기관들의 활동을 중심으로 살펴보고자 한다. 국제텔레비전아카이브연맹(Fédération Internationale des Archives de la Télévision, FIAT), 국제영상음성아카이브협회(International Association of Sound and Audiovisual Archives, IASA) 등 공공영상아카이브 관련 국제기구에서 최근 개최한 컨퍼런스, 세미나, 포럼 등에서 발표된 여러 인공지능(AI) 활용 방송미디어 아카이브 활용 프로젝트를 소개한다. 이 글에서는 프랑스 국립방송아카이브 이나(Institut National de l’Audiovisuel, INA), 벨기에 플랑드르 공공영상아카이브 미무(Meemoo)에 대해 살펴보았다.
2. 프랑스 국립방송아카이브 이나(INA) 인공지능(AI) 프로젝트
2-1. 기관 소개
프랑스 국립방송아카이브 이나(INA)는 국립시청각기구(Institut National de l’Audiovisuel)의 약자로, 1974년 프랑스 국영방송공사(ORTF)가 해체되면서 설립된 방송아카이브 기관이다. 주요 역할은 공영 및 민영 방송기록 수집·보존·활용이지만, 아카이빙 기능 외에도 방송 전문인력 양성, 콘텐츠 제작, 방송분야 조사연구 등 콘텐츠 관련 국책연구교육 기관으로 볼 수 있다.
이나는 1995년 프랑스의 방송·영상 콘텐츠 의무제출제도가 시행된 이래 이를 담당하는 주무기관으로 방송·영상 분야 국립아카이브 운영에 있어서 세계적 모델로 평가받는 기관이다. 국제필름아카이브연맹(Fédération Internationale des Archives du Film, FIAF), 국제텔레비전아카이브연맹(FIAT), 국제영상음성아카이브협회(IASA) 등 다양한 영상아카이브 국제기구의 활동에서도 주도적 역할을 하고 있다.1) 국내에서 발행된 방송·영상아카이브와 관련한 학위논문·학술논문·연구보고서 등에도 이나는 여러 차례 소개되었으며, 1990년대 후반 한국콘텐츠진흥원 전신기관인 ‘한국방송영상산업진흥원’은 이나를 모델로 ‘방송프로그램보관소’를 설립하여 2007년까지 운영한 바 있다. 방송납본제 운영, 학술연구·교육·영상창작 등 소장콘텐츠의 다양한 공공 활용 등 여러 가지 벤치마킹 요소가 많은 기관이지만, 이 글에서는 지난 80여 년의 라디오 방송 자료, 70여 년의 텔레비전 방송 자료를 활용하여 진행한 인공지능(AI) 프로젝트를 주로 알아보고자 한다.


- 1) 최효진(2018). 국내 공공영상아카이브 관리 체계 마련을 위한 과제 : 프랑스 INA FRAME 영상아카이브 국제연수 참가를 통해 살펴본 해외 동향 분석. 기록학연구. 58호, pp.95-145.
2-2. 이나 데이터 센터
이나의 데이터 센터에서는 해외 프랑스령을 포함해 프랑스에서 방영되는 모든 공영·민영 방송사의 TV·라디오 방송프로그램을 실시간 수집하여 보존용 및 활용용 사본을 생성하여 저장, 관리한다. 방송·납본제 시행 이후 라디오 방송본은 1994년부터, TV 방송본은 2001년부터 디지털 실시간 수신으로 데이터를 수집한다. 2023년 기준 105개 텔레비전 채널, 90개 라디오 스테이션으로부터 방송본을 실시간 수집한다. 매년 1백만 시간이 입수되며 매일 15TB의 데이터가 수집된다. 2022년 기준 2,500만 시간 이상의 텔레비전 및 라디오 동영상 및 음성자료, 200만 장 이상의 사진자료, 그리고 2006년 온라인 납본제 시행 이후에 입수된 3.29PB의 웹 아카이브 데이터를 보존하고 있다. 현재 보존 중인 용량은 38PB이다. 수집된 데이터 원본은 이나 본부가 있는 파리 동남부 외곽 브리 쉬르 마른(Bry-sur-Marne)에서 관리하고, 1개 사본은 파리 북서부 외곽에 위치한 오베르빌리에(Auvervillers)에서 별도 소산 관리 중이다.
수집 이후 1차 입수된 원본은 별도 보관하고, 원본으로부터 이나의 보존용 및 활용용 포맷으로 트랜스코딩하여 사본을 생성한다. 이나는 1999-2019년 약 20년간 소장자료 전량 디지털화를 시행하는 프로젝트를 추진했는데(Institut National de l’Audiovisuel, 2020), 이 과정에서 디지털 환경 변화에 따라 중장기적으로 활용할 수 있는 적절한 보존·활용 포맷을 채택해 왔다. 현재 이나의 보존용 포맷은 JPEG 2000, 활용용 포맷은 H.264이다. 송출 형태에 따라 다양한 포맷의 원본 파일이 입수되면, 이나의 시스템으로 지원 가능한 포맷인지 여부를 식별하여 지원 가능하지 않은 포맷인 경우 필요에 따라 포맷을 변환한다. 원본 및 사본은 테이프라이브러리(LTO6)에 장기보존되며, 이중보존을 위한 백업본도 자동 생성된다.

2-3. 이나 인공지능(AI) 프로젝트 개요
이나는 아카이브 수집 및 관리뿐만 아니라 영상창작·각 급 학교 교육·학술 연구 등 공적 목적으로 수집된 콘텐츠를 활용하는 데 있어서 프랑스 국내외에서 공공 영상아카이브의 세계적 모델이었다. 하지만 오랜 기간 수집·보존한 방대한 콘텐츠를 대중에게 효율적으로 제공하고 있지 못한다는 이나 안팎에서의 평가가 계속되었다. 이에 따라 소장자료 전량 디지털화 사업(1999-2019)을 추진한 지 10년 정도 지난 2010년대 초반부터 수집된 데이터 분석을 효율적으로 하여 영상데이터의 정보를 읽어내기 위한 다양한 방법을 이나 R&D부서(INA Recherche)2)를 중심으로 연구하기 시작했다. 이나의 AI 기반 프로젝트는 방대한 미디어 데이터를 분석하고 시각화하여 대중에게 더 쉽게 접근할 수 있도록 돕는 것을 목표로 하고 있다. 다양한 분석 도구를 개발·적용하여 미디어 분석의 객관성을 강화하고, 사회적 논의를 위한 중요한 데이터 소스를 제공하고자 한다(Poupeau, 2021. 12. 10).
특히 인공지능(AI) 기술을 통해 다양한 미디어 데이터를 분석하고 시각화함으로써, 정치인들의 화면 출연 시간, 성별에 따른 방송 참여 비율, 뉴스에서 자주 언급되는 장소와 인물 등을 분석했다. 또한, 음성 인식 및 텍스트 변환, 얼굴 인식, 오디오 분석(남성/여성 음성 구분), 이미지 분류 등의 다양한 AI 알고리즘을 활용하여 데이터를 처리한다.
데이터를 처리하는 몇 가지 분석도구를 소개하면 다음과 같다. 오픈소스 도구인 “InaSpeechSegmenter(이나스피치세그멘터)”는 음성을 분석하여 남성, 여성, 음악, 소음 등을 구분하는 AI 도구로, 방송에서 성별에 따른 발언 비율을 분석하는 데 사용된다. InaSpeechSegmenter는 합성곱 신경망(CNN) 모델을 사용하여 음성, 음악, 그리고 오디오 비주얼 스트림에서 화자의 성별을 자동으로 감지한다. 이나는 프랑스 방송미디어규제기관인 아르콤(l’Autorité de régulation de la communication audiovisuelle et numérique, Arcom, 구 CSA)과 약 3년간의 협업을 거쳐 이 도구를 이용해 지난 2021년 텔레비전과 라디오의 여성 출연자 출연빈도, 발언 시간, 여성출연 방송프로그램의 내용분석 등을 수행했다(l’Autorité de régulation de la communication audiovisuelle et numérique, 2022. 3. 8).
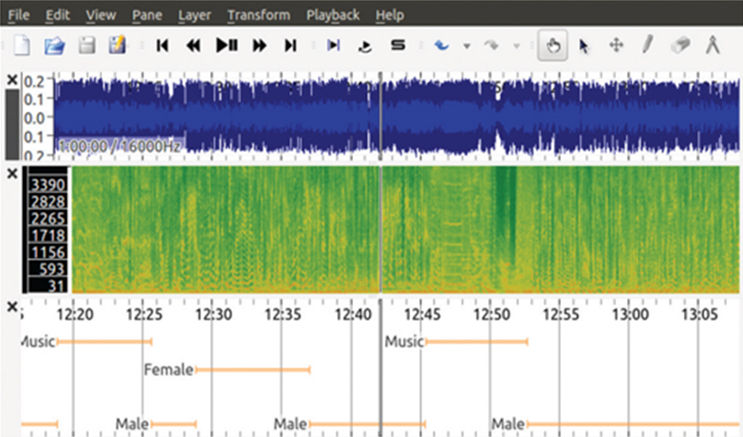
한편, 프랑스 르망 대학교와 함께 이나가 소장한 70만 시간의 텔레비전 및 라디오 방송 프로그램을 분석했다(Doukan, David 외, 2024). 미디어에서의 젠더 양적 연구로는 가장 큰 규모의 연구이다. 여성은 텔레비전과 라디오에서 평균적으로 발언 시간의 1/3을 차지한다. 수집된 데이터의 정량적 분석을 통해 시청각 미디어에서 강력한 불균형을 과학적으로 정량화한 것이다. 2010년부터 2018년까지 여성 발언 비율이 4.7% 증가했음에도 불구하고, 모든 채널에서 여성이 남성보다 덜 말하는 것으로 나타났다. 조사 대상 채널을 불문하고, 여성이 남성보다 더 많이 발언한 경우는 없었다. 여성 대상 채널(Téva, Chérie 25)에서는 발언 시간이 거의 동등하게 나타나지만, 스포츠 채널에서는 여성 발언 비율이 가장 낮게 나타났다(L’Équipe, Eurosport). 공영 채널에서는 여성의 발언 시간이 가장 두드러지게 증가했으며(+7.2%), 주요 일반 채널 중에서는 M6(40.5%)와 TF1(35.6%)에서 가장 높은 여성 발언 비율을 보였다. France 24채널에서는 발언 시간이 거의 균형을 이루며 여성 발언 비율이 약 45%에 달했다. 한편 이 라디오 방송의 경우, 2001년부터 2018년까지 여성 출연자 발언 시간은 9.2% 증가했으나, 특히 청취율이 높은 시간대에는 여전히 격차가 존재한다. 특히 공영 라디오 방송에서 여성 출연자의 출연이 더 두드러지는 것으로 나타났다. 이 데이터는 프랑스 공공데이터 포털인 data.gouv.fr에 공개했다.3)
이나의 다른 데이터 처리 도구인 Trombinos(트롬비노)는 70,000개의 얼굴을 자동으로 인식할 수 있는 도구로, 방송에 등장하는 인물을 식별하는 데 사용된다. 이 외에도 음성인식(Vocapia), 이미지 인식, OCR, 자동 분류, 텍스트 처리 도구가 활용되고 있다.
또한, 처리된 데이터는 Media Cloud AI(미디어클라우드 AI)라는 오픈소스 워크플로우 엔진을 통해 관리된다. 이 엔진은 프랑스 텔레비지옹(France Télévisions)과 Media-IO가 공동으로 개발했다. 이를 활용하여 이나는 자체적인 데이터센터와 클라우드 인프라를 구축하여 대규모 데이터를 저장하고 처리한다. 데이터는 다양한 데이터베이스(MongoDB, ElasticSearch, PostgreSQL 등)에서 저장, 관리, 처리된다. 데이터 수집 및 처리뿐만 아니라 처리된 데이터 관리 또한 인공지능(AI)의 힘을 빌리는 것이다.
2-4. 로고 및 상표 자동식별 및 태깅 시스템 디지인픽스(DiginPix)
DiginPix는 프랑스의 이나에서 지난 2014년부터 수행한 R&D프로젝트로, 다른 인공지능(AI) 프로젝트에 비해 비교적 잘 알려진 프로젝트이다(Lea, 2015. 7. 29). 이는 인공지능(AI)과 컴퓨터 비전 기술을 활용하여 시청각 자료에서 시각적 콘텐츠(예: 로고, 상표, 이미지 등)를 자동으로 인식하고 태깅하는 시스템이다. 이미지와 비디오에서 시각적 명명 엔티티(주로 로고와 법적 인물)를 인식하여 해당 콘텐츠를 자동으로 주석 처리한다. 즉, 방송 영상이나 사진에서 상표, 로고, 브랜드 심볼을 자동으로 감지한다. 예를 들어, 뉴스 방송이나 광고에서 등장하는 기업 로고를 AI가 자동으로 탐지하여 해당 영상에 태그를 붙일 수 있다. 이를 통해 사용자는 특정 상표나 로고가 포함된 콘텐츠를 검색할 수 있게 된다.
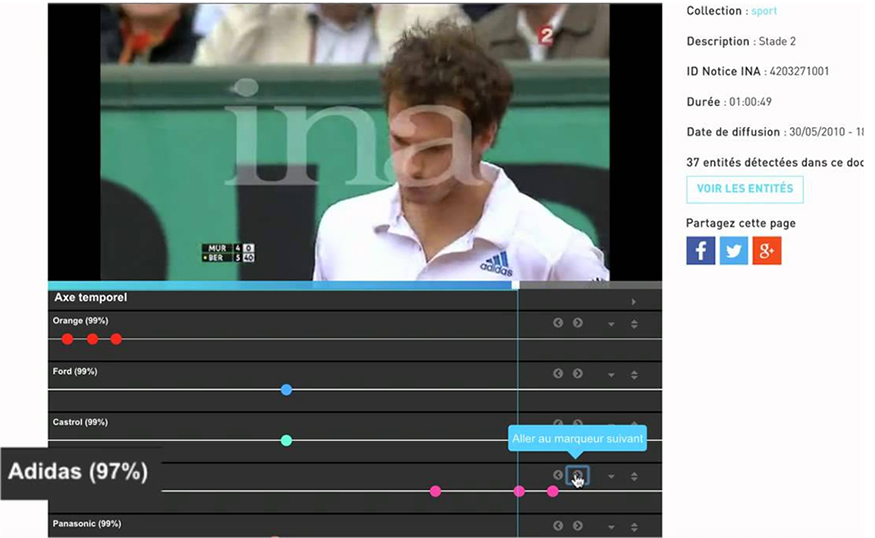
이 프로젝트에서는 이미지와 비디오에서 시각적 패턴이나 객체를 분석하여 메타데이터를 생성한다. 예를 들어, 사진 속 특정 물체나 장면을 자동으로 인식하여 콘텐츠에 태그를 추가하고, 검색 가능성을 높인다. 즉, 메타데이터 관리자(아키비스트 등)가 수동으로 메타데이터를 입력하지 않아도, 영상 속의 시각적 정보를 바탕으로 인공지능(AI)이 자동으로 메타데이터를 생성한다. 이를 통해 방대한 아카이브에서 데이터를 더 효율적으로 관리하고 검색할 수 있도록 한다. 2,000개의 테스트 이미지에서 285개의 다른 명명 엔티티를 인식하며, DigInPix는 80%의 정밀도와 30%의 재현율을 달성했다. 실시간 사용 환경에서 이미지 하나를 처리하는 데 2초 미만이 소요되며, 서버 부하에 따라 시간이 더 걸릴 수 있다.
25,000개의 엔티티(Entity) 목록을 사용하여 이미지를 분석하고, 이미지 검색 시스템을 통해 60만 개의 이미지 데이터베이스에서 일치하는 시각적 정보를 찾는다. 엔티티 목록은 위키피디아, 상위 기업 순위, 스포츠클럽, 정치 단체 등의 웹사이트에서 수집된 정보를 바탕으로 구축되었다. 법적 인물에 대한 사전은 주로 웹에서 이미지를 수집하고, 이러한 엔티티와 관련된 텍스트 표현과 이미지를 결합하여 만들어졌다. 데이터 분석 과정에서는, 동영상의 키프레임을 감지하여 중요한 변화가 일어날 때마다 이를 추출하고, 각 프레임에서 엔티티를 분석한다. 각각의 키프레임에서 식별된 엔티티를 결합하여 전체 비디오의 명명 엔티티를 분석하는 것이다. 이미지들은 SIFT(Scale-Invariant Feature Transform)4) 특징을 기반으로 해시 코드로 변환되며, 이를 통해 빠른 검색이 가능하다. 검색된 이미지와 일치하는 데이터를 기하학적으로 일관되게 처리하여 신뢰도 점수를 부여하며, 이 점수는 사용자 인터페이스에서 시각적으로 표시된다.
로고 및 상표 자동식별 및 메타데이터 생성 작업을 통해 미디어 제작에서 유용하게 활용할 수 있지만, 학술연구에서도 이를 활용할 수 있다. 연구자 및 교육자가 이나의 방대한 아카이브에서 특정 시각적 콘텐츠를 빠르게 찾아내고 분석할 수 있다. 즉, 미디어 연구자들이 특정 브랜드나 상표의 역사적 사용 사례를 분석하거나, 특정 시각적 요소를 추적하는 데 유용한 도구이다. 이를 통해 미디어 연구와 분석이 한층 더 체계적이고 효율적으로 진행될 수 있다. 예를 들어, 특정 시대에 어떤 상표나 브랜드가 미디어에서 많이 사용되었는지 분석하거나, 역사적 영상에서 중요한 시각적 요소를 추적하는 데 사용할 수 있다.5)
- 4) 컴퓨터 비전에서 많이 사용되는 이미지 특징 추출 알고리즘이다. 1999년 David Lowe에 의해 개발된 SIFT는 이미지의 스케일(크기)과 회전 변화에 강인한(invariant) 특징을 추출하는 방법이다. 이를 통해 동일한 물체를 다양한 크기와 각도로 촬영했을 때도 그 물체의 특징을 일관되게 검출할 수 있다.
- 5) Letessier, P., Hervé, N., Joly, A., Nabi, H., Derval, M., & Buisson, O.(2015. 6. 22). DigInPix: visual named-entities identification in images and videos. Buisson In ACM International Conference on Multimedia Retrieval (ICMR), Shanghai, China.; Hervé, N., Letessier, P., Derval, M., & Nabi, H.(2015. 10. 13). Amalia.js : an Open-Source Metadata Driven HTML5 Multimedia Player. In Open-Source Software Competition, ACM Multimedia Conference 2015 (MM), Brisbane, Australia.
2-5. 이나의 오픈 데이터 미디어 분석 프로젝트
한편, 이나는 2023년부터 AI로 추출된 미디어 분석 데이터를 일반 대중이 접근할 수 있도록 하는 데 방점을 둔다. 지금까지 이나의 자료를 이용하기 위해서는 법적 기탁 제한으로 인해 인증된 연구자들만 국립도서관 열람실 등에서 제한적으로 접근할 수 있었다. 본 프로젝트를 통해 카탈로그 등 콘텐츠 관리 담당자들이 메타데이터의 수집 및 큐레이션을 관리하여 처음으로 콘텐츠 검색이 가능해지는 것이다. 메타데이터는 다양한 AI 기술을 통해 생성된 데이터와 통합되어 데이터베이스에 추가되며, 이를 통해 의무제출제도에 의해 수집된 텔레비전 및 라디오 국가기록물에 대한 대중의 접근 기회를 확대할 수 있게 되었다.
사람이나 기계가 생성한 데이터를 기반으로, 우리는 TV 뉴스에서 가장 많이 등장하거나 언급된 인물, TV 및 라디오 채널에서 남성 대 여성 화자의 분포, 뉴스 채널에서 가장 많이 언급된 장소와 국가 등을 시각화한 데이터를 생성한다. 이러한 시각화는 동적이며 이용자 요구에 따라 필터링할 수 있다. 지금까지 입수된 데이터를 바탕으로 장소 엔티티 36,150개, 인물 엔티티 94, 354개, 얼굴인식 객체 74,438개 등을 식별해 냈다(Kogkitsidou, Eleni., Jaafar, Hedi Ben. & Roche-Diore, Axel., 2023. 10. 19).
이나는 인공지능(AI)을 활용한 아카이브 서비스 제공에 있어 고도의 데이터 품질 확보, 대중이 이해할 수 있는 가독성 있는 데이터 표현, 일관된 분석 결과 제공, 그리고 즉각적인 오류인식 및 정정 등이 앞으로의 도전 과제라고 보고 있다. 먼저, 국가기록물로서 의무제출 자료를 대국민 공개하기 위해서는 공개할 데이터를 정확하게 분석하여 양질의 데이터품질을 확보해야 한다. 즉, 시청각 콘텐츠에서 AI가 추출한 데이터가 정확하고 의미 있게 제공되는 것이 중요하다는 의미이다. 이나는 매일 방송되는 텔레비전 및 라디오 방송을 24시간 실시간 수집하는데, 실시간 수집과 함께 수집된 방송콘텐츠를 지속적으로 기록하고, 추출된 데이터가 오류 없이 정확하게 분류되도록 관리해야 한다. 한편 대중에게 제공되는 데이터가 이해하기 쉽고, 이용자 맞춤형이면서도 오류가 없도록 보장하는 것이 필요하다. 예를 들어, 특정 날짜에 4시간 동안 스탈린의 얼굴이 잘못 인식되거나, 유머러스한 이름이 데이터에 나타나는 문제가 발생할 수 있다. 그리고 알고리즘에 의해 분석된 데이터를 제공하는 데 있어, 언제나 일관된 결과를 제공하는 것이 중요하며, 잘못된 엔티티 인식 문제를 처리하는 것도 과제이다.

3. Challenges
Results consistency over time
- 2022 : Algorithm 1 → "Antoine du pont"
- 2024 : Algorithm 2 → "Antoine Dupont"
3. 벨기에 플랑드르 공공영상아카이브 미무(Meemoo) “공유된 인공지능(Shared AI)” 프로젝트
3-1. 기관 소개
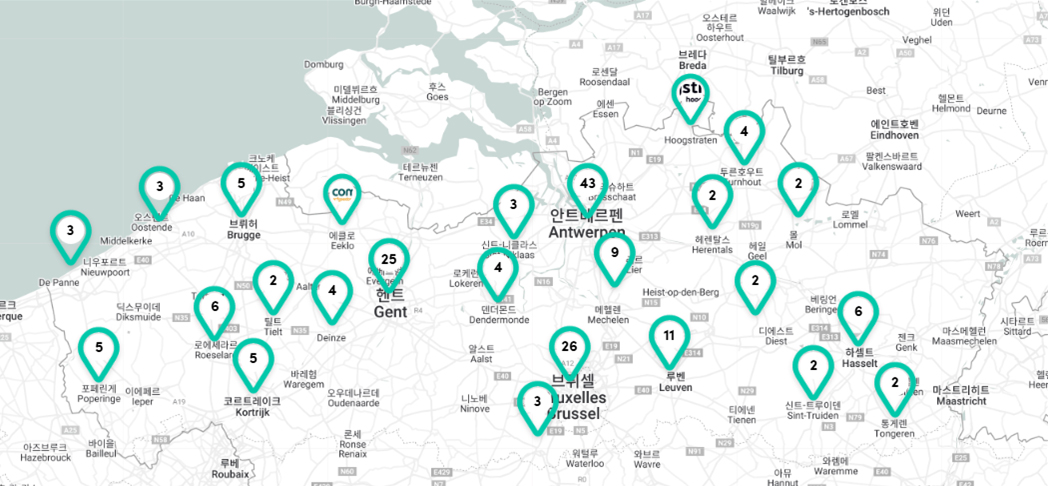
벨기에 미무(Meemoo)는 벨기에 내 플랑드르어권 지역 175개 기관(2023년 기준) 시청각 기록 수집, 관리 및 서비스를 전담하는 기구이다. 벨기에 플랑드르 공동체 정부6)가 공적 자금으로 문화·미디어·공공기관 디지털 아카이브 구축 및 운영을 지원하는 비영리기관(non-organisation)으로, 플란데런어권 방송사 VRT를 비롯해 175개 문화기관의 콘텐츠를 영구보존하고 디지털로 보관된 콘텐츠에 대한 대국민 접근을 지원한다.
일반적으로 아카이브 기관이 자체 수집부터 보존, 관리, 활용 등을 수행하는 것과 달리, 이 기관은 특정 컬렉션을 소장하지 않고 디지털아카이빙 전문 기관으로서 유관 문화기관(필름아카이브, 방송사, 박물관, 도서관 등 문화기관)의 소장 자료의 관리·대국민 공개를 위탁받아 디지털화하고 디지털 자원에 대한 장기보존과 활용(교육, 연구, 시청) 플랫폼 등을 제공하는 ‘코디네이팅’ 기관이다. 미무는 3개 문화기관이 통합되어 2020년 출범한 공공영상아카이브로, ‘플랑드르 공공영상아카이브 기관(Vlaams Instituut voor (Audiovisuele) Archivering, VIAA Flemish Institute for (Audiovisual) Archiving)’의 150여 곳 기관의 소장기록물을 위탁 관리하면서 VIAA의 고유 기능인 공공 영상·음성 디지털 아카이브 관리와 공공활용을 주요 기능으로 한다.
- 6) 벨기에는 연방 정부(Federal Government of Belgium) 밑에 3개 지역(플랑드르 지역, 왈롱 지역, 브뤼셀 수도권 지역)이 4개 언어(네덜란드어, 프랑스어, 독일어, 네덜란드어-프랑스어 이중지역) 지역에 따라 3개 공동체(플랑드르어권 공동체(네덜란드어권), 프랑스어 공동체(프랑스어권), 독일어 공동체(독일어권))를 구성하고 있다. 3개 지역정부는 부동산과 경제 정책을 담당하고, 3개 공동체 정부는 언어·교육·문화 정책을 담당한다. 본 연구에서 알아보고자 하는 미무는 3개 공동체 정부 가운데 플란데르어권 정부의 아카이브 기관이다.
3-2. 콘텐츠 파트너 기관과의 협약(Collaborative Agreement) 기반 수집
미무는 방송·영상·문화·예술 등 각 분야에서 이미지, 음성, 신문 형태의 플랑드르어권 지역 문화의 과거를 디지털 형태로 보호하는 (Safeguard the past in digital form) 역할을 총괄하는 기관이다. 2023년 기준 콘텐츠 파트너는 175개 기관이지만, 이 수는 매년 늘어나고 있다. 관리를 의뢰한 콘텐츠 파트너 기관의 문화자원에 대해 대국민 접근이 가능하도록 복수의 플랫폼을 운영한다. 대국민 접근 플랫폼 외에도 파트너들을 위한 별도의 플랫폼을 운영하여 기록물 소장기관이 상시적으로 관리·활용 현황을 모니터링할 수 있도록 한다.
입수데이터 관리를 위한 전자기록 장기보존 메타데이터 표준인 PREMIS7) 표준을 준용하고 파트너 기관과의 협약(Collaborative Agreement)을 바탕으로 파트너 기관으로부터 아날로그 매체 혹은 디지털 데이터를 입수한다. 복수의 기관이 소장한 자료를 하나의 스토리지에 통합 관리하는 만큼 미무와 파트너기관 사이의 협약은 매우 중요하다. 미무는 매일 150여 곳 기관으로부터 25TB 용량의 데이터를 입수 받기 때문에, 기관마다 협약을 통해 입수부터 관리, 활용에 이르기까지 자동화했다. 따라서, 미무는 입수에서 활용에 이르는 관리체인(chain from import to re-use) 유지에 각 기관과의 협약을 중시한다.
| 벨기에 미무-파트너 기관 협약 내용 |
|---|
|
수많은 기관으로부터 입수 받는 데이터가 관리될 수 있도록 미무는 『디지털 컬렉션 입수(Influx of Digital Collection)』프로젝트를 추진했다. 기관마다 생성되는 디지털 포맷은 다양하지만, 미무의 시스템에는 콘텐츠 유형별로 하나의 인제스트 포맷(a single photo, video or audio)을 정하여 파일과 관련 메타데이터를 입수한다. 이를 좀 더 효과적으로 이행하기 위해 2021년까지 입수 절차 표준화를 가능하게 하는 여러 디지털 객체 입수 방법을 개발했다.
이러한 과정을 거쳐 현재 관리하는 175개 파트너의 디지털 객체의 수는 760만 점, 용량으로는 25.8PB이다. 지금까지 디지털화한 아날로그 매체 수는 54만 4천여 점 이상이다. 2023년, 미무 디지털 아카이브에 입수된 디지털 객체는 1백만여 점, 데이터 용량으로는 2.5PB 정도이다.
이러한 협약 기반 협업과정을 대표적으로 하는 기관이 플랑드르 공영방송 VRT이다. VRT방송사는 2016년부터 매일 3TB 용량에 달하는 방송콘텐츠를 미무아카이브 시스템에 전송한다. VRT의 디지털데이터 외에도 1990년대 이전의 필름이나 비디오테이프 등 아날로그 매체의 디지털화 관리도 미무에 의해서 이루어지고 있다. 2011-2015년 VIAA(미무의 전신)는 VRT방송사의 VHS컬렉션(1987-2005년 녹화본) 4만 6천여 점(16만 시간 분량)을 디지털화했다. 이는 방영 당시 법적 근거에 의해 의무적으로 방송사가 녹화해야 했던 ‘보존본’으로, 플란데런어권 방송문화를 담고 있는 중요한 자료이다. VRT는 필름으로 텔레비전 프로그램을 제작·방영했던 유일한 방송사로, 1953년부터 1990년까지 생산된 약 5만 4천여 점의 VRT 필름 컬렉션 관리를 미무에게 의뢰했다. 미무가 전담하여 디지털화 작업 및 DB구축 작업을 하지만, VRT 또한 보존, 디지털화, 활용 과정에서 근본적인 업데이트 작업을 함께 수행한다.
입수된 데이터는 기본적으로 분산보존을 원칙으로 한다. 미무가 위치한 겐트(Ghent)와 이곳에서 약 40km 떨어진 도시인 우스트캠프(Oostcamp) 두 곳에 데이터 센터를 두고, 각각 사본을 보존하며, 여기에 더하여 클라우드를 활용해 2차 사본을 미러링(miroring)한다. 그리고 수장고에 3차 사본을 관리하여 결과적으로는 4개 사본을 만들고 관리한다. 1개 원본 콘텐츠를 입수하면, 보존·활용·백업용 3개 사본을 생성하여 관리하고, 이는 온라인 플랫폼에서의 대국민서비스 제공을 위해 보존 파일, 저해상도(Proxy) 파일과 메자닌(Mezzanine) 파일 생성을 자동화하여 관리 대상 콘텐츠의 활용도 제고를 위해 노력한다.
3-3. 플랑드르 문화유산 디지털전환 프로젝트 : GiVE프로젝트
지난 2022년부터 2023년 말까지 미무는 VRT방송사를 포함해 미디어·문화 부문 120개 기관의 16만 시간에 달하는 동영상 자료의 메타데이터를 개선하기 위한 프로젝트를 수행했다. 이 프로젝트는 음성-텍스트 변환(Speech-to-Text, STT), 얼굴 인식, 엔티티 추출 알고리즘 등을 활용하여 진행되었다. 미무는 STT 상용 서비스를 사용하는 동시에 장기적인 비용-편익 분석, 타 기관 벤치마킹, 개인정보 보호 고려 사항을 기반으로 자체적으로 인물 식별 도구를 개발했다(Verplancke, Nico, 2023. 10. 20).
이 프로젝트는 이른바 플랑드르 공동체 정부의 “GiVE 프로젝트”의 일환으로 추진되었다. 2021년 말부터 추진된 GiVE 프로젝트는 플랑드르 유산의 디지털화를 촉진하기 위한 Gecoördineerd Initiatief voor Erfgoeddigitalisering(Coordinated Initiative for Flemish Heritage Digitization)의 줄임말이다. 해당 프로젝트는 음성-텍스트, 명명 엔티티 인식(Name Entity Recognition, NEP), 얼굴 인식 등의 AI 기술을 활용하여 유산 자료의 메타데이터를 풍부하게 만드는 것을 목표로 한다. 정부와 미디어·문화 부문에서 각 기관의 콘텐츠가 서술적 메타데이터의 부족으로 인해 쉽게 검색되지 않는 문제를 해결하고자 이와 같은 프로젝트가 추진된 것이다. 59개 기관 컬렉션의 245개 예술작품, 8개 문화유산 기관 소장 63만여 점의 신문, 127개 기관의 16만 시간 동영상 및 음성자료를 대상으로 한다.

3-4. 공유된 인공지능(Shared AI) 프로젝트
특히, 미디어 부문에서는 2023년 “공유된 인공지능(Shared AI)”이라는 이름으로 별도의 프로젝트를 추진했다. 이 프로젝트에서는 VRT 및 지역 방송사들과 협력하여 지역 맥락에서 미디어 콘텐츠 메타데이터를 강화하는 데 중점을 둔다. VRT는 이미 인공지능(AI)을 통한 메타데이터 강화에 대한 여러 가지 경험을 쌓아왔으며, 이에 따라 미무와 함께 VRT는 프로젝트 공동 추진 주체로 나섰다.
미무가 관리하는 동영상 영상자료에 포함된 인물에 관한 사전을 구축한 후 해당 인물사전과 대조를 통해 입수된 영상자료의 인물정보를 자동 인식하도록 하는 AI 기반 소프트웨어를 개발한 것이다. 지역 방송사인 AVS, BRUZZ, De Buren, RING TV, RMM, RTV는 그들의 편집 프로세스 내에서 워크플로우를 구현하는 다양한 방법을 고려하는 데 협력한다. 앞서 살펴본 미무의 기관 소개에서 알 수 있듯이, VRT 및 지역 방송사들과의 구조적 협력은 새로운 일이 아니다. 미무는 이전부터 여러 해 동안 VRT 등 방송사의 아카이브 자료를 보관, 디지털화하고 접근성을 제공해 왔다. 이러한 맥락에서 미무는 Shared AI와 같은 프로젝트에서 주도적인 역할을 할 수 있었다.8)
Shared AI의 시작은 미무아카이브 시스템 내에서 아카이브 콘텐츠를 검색하는 데 어려움이 있다는 점에서 비롯되었다. 미무가 관리하는 파트너기관들의 콘텐츠는 종종 제대로 설명되지 않거나 전혀 설명되지 않아 찾기 어렵거나 아예 검색이 불가능하며, 이는 재사용을 촉진하는 데에도 장애가 된다. 해결책은 메타데이터 추가 및 정확한 기술(Description)에 있다. 하지만 관리 중인 콘텐츠 메타데이터를 전량 수동으로 입력하는 데는 엄청난 시간이 소요된다. 따라서 우리는 인공지능(AI)과 기계 학습 기법을 사용한 자동화된 설명 프로세스에 중점을 두었다. 작은 조직이 자체적으로 인공지능을 배포하는 것은 어려운 일이다. 이에 따라 그래서 Shared AI의 핵심 요소 중 하나는 협업의 수준이다. 지역 방송사의 아카이브를 VRT 아카이브와 협력하는 과정에서 미무는 재원 확보·기술 전문성·인식 대상 인물정보 편집 등을 결정하는 역할을 한다.9)
16만 시간의 오디오와 비디오 파일에서 음성 텍스트 변환 및 엔티티 인식을 통해 130,000개의 항목에 메타데이터를 추가했다. 얼굴 인식은 100,000건 항목에서 수행되었으며, 120,000시간 이상의 미디어 자료를 대상으로 작업했다.

Focus on Face Recognition: what do we want?
- Identify faces and cluster like
- Match with known faces/persons
- Identify frequent unknowns
- Manage and expand shared reference set of known faces
Europese Unie, EFRO, meemoo
미무의 얼굴 인식은 비디오 속 인물의 얼굴을 감지하고, 해당 인물이 누구인지를 파악하는 데 중점을 둔다. 이는 얼굴 인식 기술을 사용하여 반복적으로 새로운 얼굴을 감지하고, 기존 참조 세트와 일치하는지 확인하는 방식으로 이루어진다. AI를 활용해 3,300만 명의 인물을 감지하고, 이 중 20만 8천 개의 얼굴을 2,500명의 인물과 매칭시켰다. 그 결과 330만 개의 얼굴, 650만 개의 이름을 식별했고, 다양한 언어로 5억 개 이상의 단어를 전사(Transcribe)했다. 누군가 여러 아카이브에 등장하면 동일한 라벨을 붙이고, 위키데이터(Wikidata) 링크로 연결하여 다양한 아카이브 자료 간에 사람과 장소를 통일성 있게 식별할 수 있도록 했다.
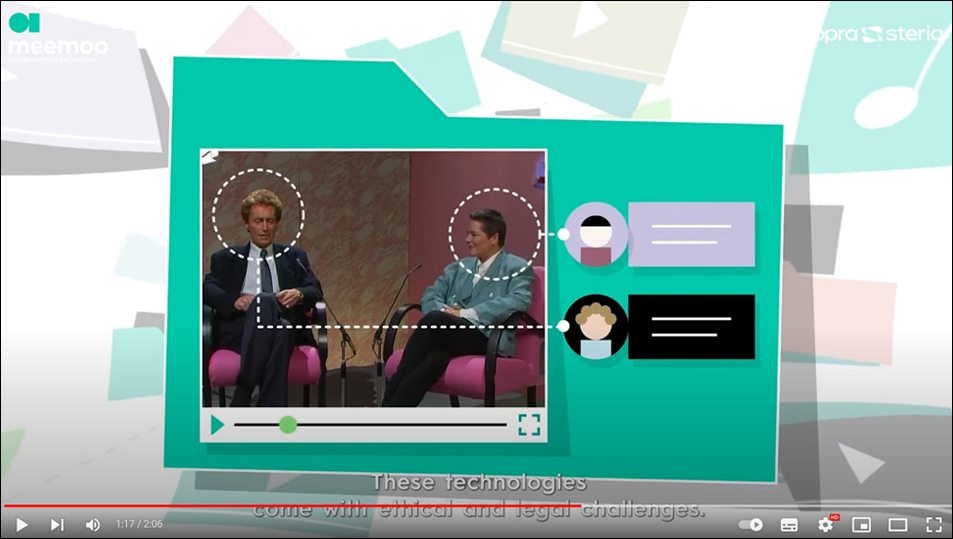
메타데이터 정확성을 보장하기 위해 인물 레퍼런스 세트(Reference Set)를 제작하고, 매일 입수되는 파트너 기관들의 영상자료 가운데 인물 정보를 레퍼런스 세트와 대조하여 인물 메타데이터를 자동으로 태깅한다(Verplancke, Nico, 2023. 10. 20). 즉, 레퍼런스 세트는 얼굴 인식에서 중요한 역할을 하며, 특정 인물을 식별하고 해당 정보를 위키데이터나 파트너 기관의 데이터와 연결한다. 이 세트는 기관 간에 공유되며, 인물 인식에 있어 투명성을 보장하는 중요한 요소이다.
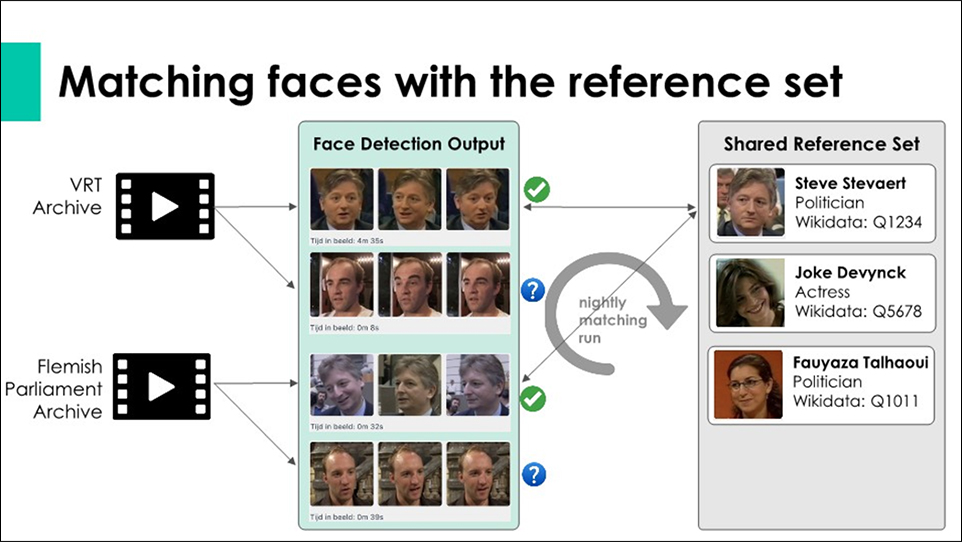
Matching faces with the reference set
- VRT Archive, Flemish Parliament Archive
- Face Detection Output
- nightly matching run
- Shared Reference Set
또한 파트너 기관들과 함께 윤리적, 개인정보 보호 문제를 조사하고 논의하는 협력 트랙을 별도로 두고, 그 결과를 프로젝트 산출물에 포함시켰다. 기계가 인식하는 정보에 대한 정확성 여부, 역사적 맥락 확인 등을 위해 파트너 기관 외에 역사학, 사회학, 미디어학, 법학 분야 전문가가 이에 함께 한다. 이 프로젝트의 일환으로 미무는 공공 및 역사적 인물을 식별하는 협력적인 접근 방식을 창안했으며, 여러 기관이 레퍼런스 세트를 함께 구축할 수 있도록 돕는 ‘Visual Name Authority’ 도구를 개발했다.

Ethical aspects
- Collaboration with Knowledge Center for Data and Society
- Multiple stakeholder workshops, focusing on face recognition
- Shared insights and principles
meemoo
3-5. 중장기 계획
생성된 메타데이터는 미무에서 지속적으로 보존될 뿐만 아니라, 참여하는 방송사들이 각 사의 미디어 관리 시스템 및 플랫폼에 메타데이터를 통합할 수 있게 된다. 미무는 이러한 데이터 재사용이 향후 데이터 강화 프로젝트를 위한 이상적인 기반이 될 것으로 보고 있다. 미무는 또한 이 메타데이터를 일반 대중에게 어떻게, 그리고 어느 정도까지 접근 가능하게 할지에 대해서도 검토하고 있다.
미무는 향후 GiVE 및 공유된 인공지능 프로젝트 결과물을 더 많은 대국민 서비스로 통합할 계획이다. 그리고 국제적인 협력을 통해 프로젝트를 확장할 가능성을 모색하고 있다. GiVE 및 ‘공유된 인공지능’ 프로젝트를 기반으로, 콘텐츠 파트너 기관들과 함께 법적 및 윤리적 문제를 지속적으로 논의할 예정이다. 인물 인식을 예로 든다면, 이러한 논의에는 어떤 인물을 인식할지, 누구를 인식하지 않을지, 그리고 이러한 결정을 누가 내릴 것인가에 대한 질문들이 포함된다. 또한, 특정 도시나 지역에서 중요한 인물이 플랑드르어권 전체에서 중요한 인물인가 등을 결정하기도 한다. 미무를 포함해 문화 및 미디어 아카이브 각 기관은 비슷한 딜레마와 도전에 직면해 있으며, 이러한 문제에 대해서도 함께 해결해 나갈 예정이다.
4. 마치며
지금까지 프랑스 이나와 벨기에 미무 등 공공영상아카이브 기관의 인공지능(AI) 프로젝트를 살펴보았다. 두 기관의 사례에서 몇 가지 시사점을 찾을 수 있다. 두 기관의 역사와 설립 및 운영 재원, 그리고 이 글에서 살펴본 인공지능 프로젝트의 성격이 각각 다르지만, 두 사례의 공통점을 중심으로 국내 방송사와 미디어 기관이 참고할 만한 점을 짚어보았다.
먼저 데이터 수집의 일원화 및 안정성이다. 두 기관 모두 오랜 시간 데이터 센터를 운영하여 각각 프랑스와 벨기에 플랑드르 지역 영상기록물 데이터를 주요 서버에 일원화하여 관리한다. 기관의 정책에 따라 3중 또는 4중 사본 생성과 이중화, 소산 관리 등을 체계적으로 하고 있다. 인공지능 기반 사업의 재료가 되는 데이터의 안정적인 관리는 국내 주요 방송사와 미디어 기관들이 가장 참고해야 할 점이다.
둘째, 인공지능을 활용한 데이터 분석에서 신뢰성 및 정확성 확보를 위한 노력을 참고해야 한다. 단순히 기계학습에 의한 자동식별, 자동 분류 등에 의존하지 않고, 다양한 분야의 전문가들과 협력하여 분석된 데이터가 정확한 정보를 담고 있는지, 분석 결과에 오류는 없는지, 성별이나 지역, 정치적 성향 등 한 쪽으로 편향된 분석은 없는지 등을 지속적으로 모니터링한다. 벨기에 미무는 데이터를 제공하는 콘텐츠 파트너 기관, 역사학자, 법학자 정기적인 논의를 하며 논의 결과를 데이터 분석에 반영하는 절차를 마련했다. 특히 얼굴인식 대상의 인물이 플랑드르 역사에서 중요한 인물이 잘 반영되었는지, 혹은 누락된 인물은 없는지, 그리고 분석 결과가 정확한지, 분석 결과로 인해 초상권 등 권리관계 침해는 없는지 등을 깊이 있게 논의하는 과정은 추후 국내에서 비슷한 사업 진행 시 참고해야 할 것이다.
셋째, 이처럼 당대 미디어 데이터를 거의 전량에 가깝도록 수집하는 ‘포괄적 수집’과 이를 토대로 한 정확하고 신뢰할 수 있는 인공지능 활용 분석의 목적은 공적으로 창작·교육·연구 등에 활용 가능한 데이터를 공개하는 데 있다는 점도 주목할 대목이다. 프랑스 이나는 ‘오픈 데이터 미디어 분석 프로젝트’를 2023년부터 시작하여 일반 시민들이 이해할 수 있는 데이터를 내놓겠다는 계획을 하고 있다. 이를 통해 텔레비전 및 라디오 의무제출 기록물에 대한 대중의 접근 기회를 확대하고자 한다. 벨기에 미무의 얼굴인식 프로젝트는 기관이 관리 중인 170여 개 기관의 영상데이터 중 인물의 얼굴을 인식하여 좀 더 정확히 누가 출연한 영상물인지 확인할 수 있도록 한다. 현재는 데이터 분석 단계에 있고 분석 결과는 프로젝트에 참여한 VRT 공영방송 및 지역 방송사 등에 제공되어 각 사에서 콘텐츠 제작 등에 재활용된다.
마지막으로 이러한 인공지능 기반 프로젝트를 진행하는 데 있어서 미디어 당국의 정책적 지원 또한 중요하다. 프랑스 이나의 인공지능 사업은 이 글에서 구체적으로 다루지는 않았지만, 프랑스 문화부 등 정부 관계기관이 최근 방점을 두는 ‘디지털 퍼스트’ 전략의 일부이기도 하다. 지금의 ARCOM 출범 전 프랑스 방송통신위원회인 CSA는 프랑스 이나, 프랑스텔레비지옹 등 공영방송기관을 관리감독하는 여러 지표 가운데 대국민 디지털 접근을 얼마나 보장하는가가 오래전부터 중요한 지표였다. 이 글에서 살펴본 인공지능 프로젝트에 앞서 교육부, 프랑스텔레비지옹과 함께 구축한 교육용 방송아카이브 룸니(Lumni), 방송콘텐츠계 넷플릭스라고 불리는 마들렌(Madelen) 등은 프랑스 국민들에 대한 방송콘텐츠 접근권 확대의 한 과정인 것이다.10) 벨기에의 미무 또한 플랑드르 정부가 2021년 말부터 추진한 GiVE프로젝트의 한 과정으로 ‘공유된 인공지능’이 추진되었음을 확인했다. GiVE프로젝트는 플랑드르 공동체 정부의 큰 재원이 투입된 사업으로, 플랑드르 문화 및 미디어 디지털화 및 대국민 접근권 확대에 그 목적이 있다. 이미 국내에서도 적지 않은 공공 예산이 투입되어 인공지능 사업이 추진되었지만, 무엇을 목적으로 공공데이터를 수집·분석했는지 알기 어렵다는 비판을 받은 사업도 많다. 향후 국내 방송 미디어 부문에서 인공지능 후속사업을 추진하는 데 있어서 두 사례와 같이 명확한 공적 활용을 위한 정책적 지원이 뒷받침되기를 기대한다.
- 10) 프랑스 이나의 방송콘텐츠 공적 활용에 대해서는 정회경·김희경·최효진(2022) 참고.
참고문헌
- 국내자료
- 1) 정회경·김희경·최효진(2022). 방송통신 콘텐츠의 공적 활용 방안. 한국방송광고진흥공사.
- 2) 최효진(2018). 국내 공공영상아카이브 관리 체계 마련을 위한 과제 : 프랑스 INA FRAME 영상아카이브 국제연수 참가를 통해 살펴본 해외 동향 분석. 기록학연구. 58호, pp.95-145.
- 3) 최효진(2021). ‘공공영상문화유산’아카이브 구축 방안 연구 : 방송·영상 컬렉션 수집 및 활용 방향. 한국외국어대학교 대학원 박사학위 논문.
- 해외자료
- 1) Amouroux, B.(2018). Feedback on 20 years of digitizing audiovisual archives. INA Frame 교육연수(2018. 6. 18.-22., Bry-Sur-Marne, France) 강의자료.
- 2) Caplan, P.(2009. 2. 1). PREMIS의 이해(Understanding PREMIS). The Library of Congress, except within the U.S.A.
- 3) Doukhan, David & Dodson, Lena & Conan, Manon & Pelloin, Valentin & Clamouse, Aurelien & Lepape, Melina & Hille, Geraldine & Meadel, Cecile & Coulomb-Gully, Marlene.(2024). Gender Representation in TV and Radio: Automatic Information Extraction methods versus Manual Analyses. 3060-3064. 10.21437. Interspeech. 2024-1921.
- 4) Hervé, N., Letessier, P., Derval, M., & Nabi, H.(2015. 10. 13). Amalia.js : an Open-Source Metadata Driven HTML5 Multimedia Player. In Open-Source Software Competition, ACM Multimedia Conference 2015 (MM), Brisbane, Australia.
- 5) Kogkitsidou, Eleni., Jaafar, Hedi Ben. & Roche-Diore, Axel.(2023. 10. 19). AI extracted media analytics made accessible to general audience, Federation Internationale des Archives de la Television (FIAT/IFTA) World Conference 2023 발표자료.
- 6) l’Autorité de régulation de la communication audiovisuelle et numérique(2022. 3. 8). La représentation des femmes à la télévision et à la radio - Rapport sur l’exercice 2021.
- 7) Lea(2015. 7. 29). DigInPix, la bibliothèque d’entités visuelles développée par l’INA.
- 8) Letessier, P., Hervé, N., Joly, A., Nabi, H., Derval, M., & Buisson, O.(2015. 6. 22). DigInPix: visual named-entities identification in images and videos. Buisson In ACM International Conference on Multimedia Retrieval (ICMR), Shanghai, China.
- 9) Poupeau, Gautier(2021. 12. 10). En quoi l’intelligence artificielle constitue pour l’INA une opportunité pour renforcer ses missions de valorisation et de conservation du patrimoine audiovisuel ?. Bibiliothèque Nationale de France, « Futurs fantastiques », la 3e conférence internationale sur l’intelligence artificielle (IA) dans les bibliothèques, les archives et les musées. 강연 영상 및 발제자료.
- 10) Verplancke, Nico(2023. 10. 20). More metadata, more happy partners: using AI in a collaborative context. Federation Internationale des Archives de la Television (FIAT/IFTA) World Conference 2023 발표자료.
- 기타
- 1) Institut National de l’Audiovisuel 홈페이지.
- 2) Institut National de l’Audiovisuel(2020). Rapport d’Activites.
- 3) Institut National de l’Audiovisuel. Research team.
- 4) Institut National de l’Audiovisuel. Women’s speaking time: 700,000 programming hours analysed.
- 5) Meemoo 홈페이지.
- 6) Meemoo(2023. 3. 14). Metadata and media: Shared AI project approved!.
- 7) Meemoo. Shared AI: metadata enrichment for the media sector.
- 8) OpenCV. Introduction to SIFT(Scale-Invariant Feature Transform).
- 9) Sopra Steria Benelux YouTube 채널. Meemoo digitises the Flemish cultural heritage using AI.